 前々回の記事でデータメッシュアーキテクチャの概要と従来のデータアーキテクチャの課題について紹介しました。前回の記事ではデータメッシュアーキテクチャを実現するための4つの基本原則について紹介しました。前回までは、データメッシュアーキテクチャの考え方について記事にしてきたのですが、今回はデータメッシュアーキテクチャを実現にするにあたっての設計方針について紹介をしたいと思います。
前々回の記事でデータメッシュアーキテクチャの概要と従来のデータアーキテクチャの課題について紹介しました。前回の記事ではデータメッシュアーキテクチャを実現するための4つの基本原則について紹介しました。前回までは、データメッシュアーキテクチャの考え方について記事にしてきたのですが、今回はデータメッシュアーキテクチャを実現にするにあたっての設計方針について紹介をしたいと思います。
- データメッシュアーキテクチャの論理アーキテクチャ
データメッシュの論理アーキテクチャ
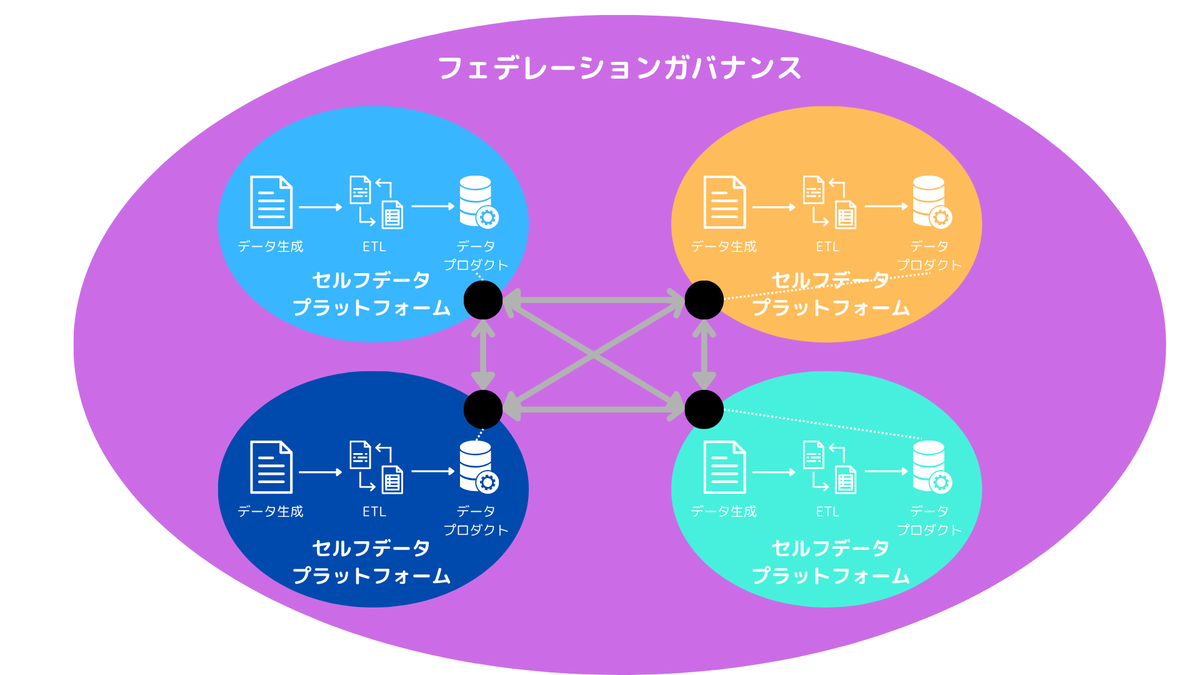
データメッシュのアーキテクチャは、各ビジネスドメインが独立したノードとして機能し、それらが相互に連携するネットワークとして構築されます。各ドメイン内では、業務システム(Operational Systems)からデータが生成され、そのデータが変換・加工されて「データプロダクト」となります。このデータプロダクトは、API、イベントストリーム、またはクエリ可能なテーブルなどの標準化された「出力ポート(Output Ports)」を通じて、他のドメインや分析ツールから利用可能になります。
このアーキテクチャ全体は、ドメインチームが利用する「セルフサービスデータプラットフォーム」と、全体を統制する「フェデレーテッドガバナンス」層によって支えられています。重要な点は、データウェアハウスやデータレイクといった既存のシステムが完全に不要になるわけではないことです。これらはメッシュの中心には位置しませんが、メッシュを構成する一つのノードとして、特定のドメインが必要とするデータプロダクトを提供・利用する役割を担うことになります。
データメッシュを構成する技術スタック
データメッシュを構成する技術スタックは多岐にわたりますが、主要なカテゴリは以下の通りです。
データストレージと処理
クラウドオブジェクトストレージ(Amazon S3やGoogle Cloud Storageなど)が、データメッシュの基盤となることが多いです。これらのストレージ上で、SnowflakeやDatabricksといったデータウェアハウスやレイクハウスプラットフォームが、各ドメインのデータプロダクトの処理・保存基盤として利用されます。
データ統合とクエリエンジン
データメッシュの思想に特に親和性が高いのが、Trino(旧PrestoSQL)のような分散クエリエンジンです。Trinoは、データを一箇所に集約することなく、複数のドメインや多様なデータソースにまたがり、その場でデータをクエリする能力を持ちます。この「クエリ・イン・プレイス」機能は、データメッシュの分散型・連合型の性質を技術的に実現する上で、極めて重要な役割を果たします。
データカタログと発見
Collibra、Alation、あるいはオープンソースのDataHubといったデータカタログツールは、「プロダクトとしてのデータ」原則における「発見可能性(Discoverability)」を担保するために不可欠です。これらのツールは、メッシュ内に存在するすべてのデータプロダクトのメタデータを集約し、検索可能な中央レジストリとして機能します。
ガバナンスとアクセス制御
Immutaのようなツールは、コードとして定義されたポリシーを異なるプラットフォーム横断で一貫して適用する能力を提供します。セルフサービスプラットフォーム自体も、暗号化、アクセス制御、監視といった基本的なガバナンス機能を提供する必要があります。
ワークフローと変換
FivetranやdbtのようなETL/ELTツール、そしてApache Kafkaのようなストリーミングソリューションは、各ドメイン内でデータプロダクトを構築するために利用されます。
データプロダクト・ライフサイクル管理(DPLM)の必要性
「プロダクトとしてのデータ」原則を実践するためには、データプロダクトのライフサイクルを体系的に管理するデータプロダクト・ライフサイクルマネジメント(DPLM)が不可欠です。
ライフサイクルの主要ステージ
一般的に、以下の4つのステージで構成されます。
構想(Ideate)
ビジネス価値を出発点として、目的、ユースケース、ステークホルダーのニーズを明確に定義します。
設計(Design)
「データコントラクト」を作成し、データ構造、品質基準、更新頻度、SLAなどを定義。これにより、発見可能性と理解可能性が担保されます。
運用化(Operationalize)
実際のデータパイプラインを構築し、テスト、デプロイ、そして継続的な監視を行います。
保守と破棄(Maintain & Retire)
利用状況をモニタリングし、価値が低下したプロダクトは適切に破棄させます。
中心的成果物:データコントラクト
このプロセスの中心には「データコントラクト」があります。これは、データプロダクトの提供者と消費者の間の公式合意書であり、スキーマ、SLA、品質メトリクス、利用条件などを明確に定義します。これにより、データプロダクトの信頼性と予測可能性が保証されます。
まとめ - 技術的依存とアーキテクチャの選択 -
データメッシュは原則としてテクノロジーに依存しない設計が望まれますが、実際に成功するには、分散化・相互運用性・セルフサービスを支援する技術が不可欠です。中でも、Trino(旧PrestoSQL)のような分散クエリエンジンは、単なる技術選択ではなく、アーキテクチャ哲学を具体化する手段です。
データを一箇所に移動することなく、ドメインをまたいでクエリを実行する
「クエリ・イン・プレイス」による連合型アクセスを実現する
これらの能力は、原則1(分散型アーキテクチャ)および原則3(セルフサービスプラットフォーム向け統一SQLインターフェース)を直接サポートします。